


Introduction
At Datazone, our mission is to simplify data engineering tasks while providing a powerful, scalable platform for managing and analyzing large-scale data. As we set out to build a comprehensive data and AI platform, we made the strategic decision to use Apache Spark and Clickhouse as our foundational engines. Why? Because they offer a perfect blend of scalability, performance, and flexibility, making them the best choices to support a wide range of data workloads.
In this blog, we'll explain why we've chosen Apache Spark and Clickhouse, and how Datazone simplifies managing data engineering tasks through these powerful engines.
Apache Spark: The Engine for Scalable and Distributed Data Processing
Apache Spark is a robust, open-source engine designed for distributed data processing, known for its ability to handle large-scale data efficiently across multiple clusters. Here's why it's at the heart of Datazone:
1. Speed and Performance
Spark's in-memory computing capability enables faster processing for large datasets. Whether it’s batch processing or real-time stream processing, Spark delivers low-latency data pipelines, making it ideal for businesses that need timely insights. Spark's performance advantages help businesses process terabytes or even petabytes of data with high efficiency.
2. Scalable Across Clusters
As a distributed system, Apache Spark can scale horizontally across multiple nodes in a cluster, making it highly adaptable to varying data sizes. At Datazone, this scalability ensures that no matter how large or complex your data pipelines grow, Spark handles the load without compromising speed.
3. Unified Data Processing
One of Spark’s key strengths is its versatility in managing different types of data workloads, whether it’s batch processing, machine learning, or real-time stream analytics. This unified processing capability makes Spark an ideal engine for the diverse workloads our customers manage within Datazone. It simplifies the tech stack by eliminating the need for multiple specialized systems.
Clickhouse: The Fast Columnar Database for Analytics
Clickhouse is an open-source columnar database specifically designed for online analytical processing (OLAP). It excels in high-performance analytics at scale, and here’s why it’s a perfect match for Datazone’s data ecosystem:
1. Blazing Fast Query Performance
Clickhouse is built for speed. Its columnar storage format allows it to read only the data necessary to answer a query, making it much faster than traditional row-based databases, especially when working with large datasets. In Datazone, this translates to sub-second query performance even on billions of rows of data, making it perfect for dashboards, reports, and ad-hoc analytics.
2. Efficient Data Storage
With its advanced compression algorithms, Clickhouse allows for much more efficient storage of large datasets. In a world where data is growing exponentially, keeping storage costs manageable is critical. Datazone’s customers benefit from reduced storage footprints while still accessing their data quickly and efficiently.
3. Handling Complex Analytical Workloads
Clickhouse excels in executing complex analytical queries, such as aggregations and multi-join queries, with a level of efficiency that few other databases can match. This makes it a natural fit for Datazone, where users expect fast insights from their data, no matter how complex the query.
How Datazone Simplifies Data Engineering with Spark and Clickhouse
While both Apache Spark and Clickhouse are powerful on their own, managing and orchestrating them in production environments can still be challenging. This is where Datazone comes in, simplifying the data engineering journey for our users.
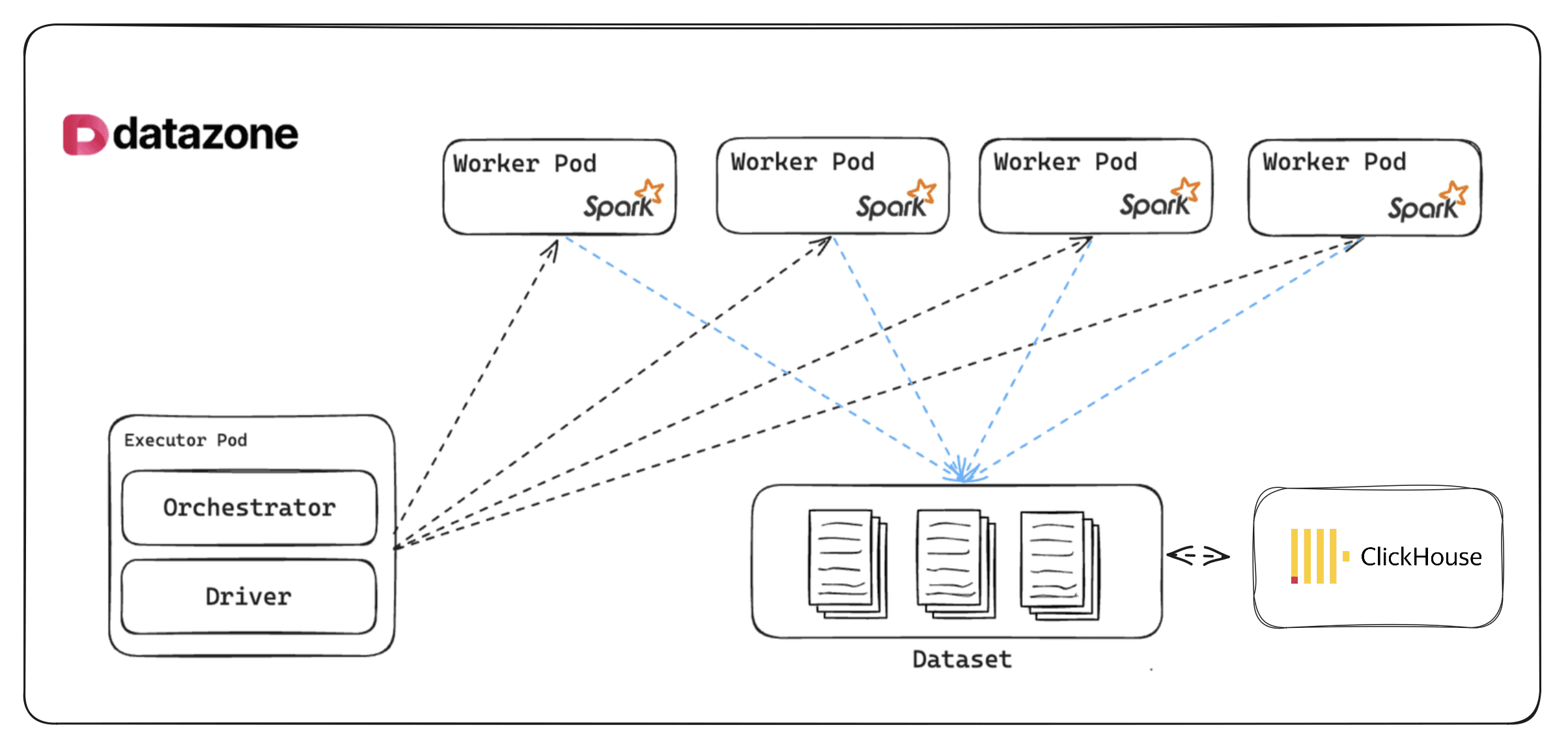
1. Unified Platform for Data Processing and Analytics
At Datazone, we’ve brought together Spark and Clickhouse into a unified, easy-to-manage platform. Instead of configuring and deploying these engines separately, Datazone offers a seamless experience where you can run your distributed data pipelines with Apache Spark and query your data at lightning speed with Clickhouse—all from one place.
2. No Need to Manage Infrastructure
Setting up clusters, managing compute resources, and optimizing storage are tasks that can eat up valuable time for data engineers. Datazone abstracts the complexity of provisioning and managing infrastructure for both Apache Spark and Clickhouse. With Datazone, users can focus on building and running their data pipelines, while we handle the backend infrastructure.
3. Automated Scaling and Resource Management
One of the most common challenges in data engineering is scaling resources as data volumes grow. Datazone automates the provisioning of resources like Datazone Compute Units (DCUs), ensuring that your Spark and Clickhouse workloads have the compute and storage they need, without the overhead of manually tuning clusters or managing servers.
4. Optimized for Cost and Performance
We understand that balancing performance and cost is critical for our users. Datazone optimizes the use of both Spark and Clickhouse to ensure you get maximum performance at the most efficient cost. For example, we dynamically provision resources based on usage patterns, reducing unnecessary overhead while ensuring peak performance when you need it most.
5. End-to-End Pipeline Orchestration
Building and maintaining data pipelines often involves multiple tools and significant manual effort. Datazone streamlines the process by allowing you to build, manage, and monitor your entire pipeline— from ingesting data, processing it with Spark, to loading and querying it in Clickhouse—all in one place. This simplifies operations, reduces errors, and accelerates time-to-insight.
Conclusion
At Datazone, we believe that choosing the right foundational technologies is key to building a powerful, scalable, and efficient data platform. By combining Apache Spark for distributed data processing and Clickhouse for high-speed analytics, we ensure that our platform delivers top-tier performance and scalability.
However, the true value of Datazone lies in how we simplify the management of these technologies. From infrastructure management to pipeline orchestration, Datazone removes the complexity from data engineering, allowing you to focus on what matters most—extracting insights from your data.
Ready to experience the power of Apache Spark and Clickhouse without the headaches of managing them? Get started with Datazone today and see how we can simplify your data workflows.
Introduction
At Datazone, our mission is to simplify data engineering tasks while providing a powerful, scalable platform for managing and analyzing large-scale data. As we set out to build a comprehensive data and AI platform, we made the strategic decision to use Apache Spark and Clickhouse as our foundational engines. Why? Because they offer a perfect blend of scalability, performance, and flexibility, making them the best choices to support a wide range of data workloads.
In this blog, we'll explain why we've chosen Apache Spark and Clickhouse, and how Datazone simplifies managing data engineering tasks through these powerful engines.
Apache Spark: The Engine for Scalable and Distributed Data Processing
Apache Spark is a robust, open-source engine designed for distributed data processing, known for its ability to handle large-scale data efficiently across multiple clusters. Here's why it's at the heart of Datazone:
1. Speed and Performance
Spark's in-memory computing capability enables faster processing for large datasets. Whether it’s batch processing or real-time stream processing, Spark delivers low-latency data pipelines, making it ideal for businesses that need timely insights. Spark's performance advantages help businesses process terabytes or even petabytes of data with high efficiency.
2. Scalable Across Clusters
As a distributed system, Apache Spark can scale horizontally across multiple nodes in a cluster, making it highly adaptable to varying data sizes. At Datazone, this scalability ensures that no matter how large or complex your data pipelines grow, Spark handles the load without compromising speed.
3. Unified Data Processing
One of Spark’s key strengths is its versatility in managing different types of data workloads, whether it’s batch processing, machine learning, or real-time stream analytics. This unified processing capability makes Spark an ideal engine for the diverse workloads our customers manage within Datazone. It simplifies the tech stack by eliminating the need for multiple specialized systems.
Clickhouse: The Fast Columnar Database for Analytics
Clickhouse is an open-source columnar database specifically designed for online analytical processing (OLAP). It excels in high-performance analytics at scale, and here’s why it’s a perfect match for Datazone’s data ecosystem:
1. Blazing Fast Query Performance
Clickhouse is built for speed. Its columnar storage format allows it to read only the data necessary to answer a query, making it much faster than traditional row-based databases, especially when working with large datasets. In Datazone, this translates to sub-second query performance even on billions of rows of data, making it perfect for dashboards, reports, and ad-hoc analytics.
2. Efficient Data Storage
With its advanced compression algorithms, Clickhouse allows for much more efficient storage of large datasets. In a world where data is growing exponentially, keeping storage costs manageable is critical. Datazone’s customers benefit from reduced storage footprints while still accessing their data quickly and efficiently.
3. Handling Complex Analytical Workloads
Clickhouse excels in executing complex analytical queries, such as aggregations and multi-join queries, with a level of efficiency that few other databases can match. This makes it a natural fit for Datazone, where users expect fast insights from their data, no matter how complex the query.
How Datazone Simplifies Data Engineering with Spark and Clickhouse
While both Apache Spark and Clickhouse are powerful on their own, managing and orchestrating them in production environments can still be challenging. This is where Datazone comes in, simplifying the data engineering journey for our users.
1. Unified Platform for Data Processing and Analytics
At Datazone, we’ve brought together Spark and Clickhouse into a unified, easy-to-manage platform. Instead of configuring and deploying these engines separately, Datazone offers a seamless experience where you can run your distributed data pipelines with Apache Spark and query your data at lightning speed with Clickhouse—all from one place.
2. No Need to Manage Infrastructure
Setting up clusters, managing compute resources, and optimizing storage are tasks that can eat up valuable time for data engineers. Datazone abstracts the complexity of provisioning and managing infrastructure for both Apache Spark and Clickhouse. With Datazone, users can focus on building and running their data pipelines, while we handle the backend infrastructure.
3. Automated Scaling and Resource Management
One of the most common challenges in data engineering is scaling resources as data volumes grow. Datazone automates the provisioning of resources like Datazone Compute Units (DCUs), ensuring that your Spark and Clickhouse workloads have the compute and storage they need, without the overhead of manually tuning clusters or managing servers.
4. Optimized for Cost and Performance
We understand that balancing performance and cost is critical for our users. Datazone optimizes the use of both Spark and Clickhouse to ensure you get maximum performance at the most efficient cost. For example, we dynamically provision resources based on usage patterns, reducing unnecessary overhead while ensuring peak performance when you need it most.
5. End-to-End Pipeline Orchestration
Building and maintaining data pipelines often involves multiple tools and significant manual effort. Datazone streamlines the process by allowing you to build, manage, and monitor your entire pipeline— from ingesting data, processing it with Spark, to loading and querying it in Clickhouse—all in one place. This simplifies operations, reduces errors, and accelerates time-to-insight.
Conclusion
At Datazone, we believe that choosing the right foundational technologies is key to building a powerful, scalable, and efficient data platform. By combining Apache Spark for distributed data processing and Clickhouse for high-speed analytics, we ensure that our platform delivers top-tier performance and scalability.
However, the true value of Datazone lies in how we simplify the management of these technologies. From infrastructure management to pipeline orchestration, Datazone removes the complexity from data engineering, allowing you to focus on what matters most—extracting insights from your data.
Ready to experience the power of Apache Spark and Clickhouse without the headaches of managing them? Get started with Datazone today and see how we can simplify your data workflows.
Introduction
At Datazone, our mission is to simplify data engineering tasks while providing a powerful, scalable platform for managing and analyzing large-scale data. As we set out to build a comprehensive data and AI platform, we made the strategic decision to use Apache Spark and Clickhouse as our foundational engines. Why? Because they offer a perfect blend of scalability, performance, and flexibility, making them the best choices to support a wide range of data workloads.
In this blog, we'll explain why we've chosen Apache Spark and Clickhouse, and how Datazone simplifies managing data engineering tasks through these powerful engines.
Apache Spark: The Engine for Scalable and Distributed Data Processing
Apache Spark is a robust, open-source engine designed for distributed data processing, known for its ability to handle large-scale data efficiently across multiple clusters. Here's why it's at the heart of Datazone:
1. Speed and Performance
Spark's in-memory computing capability enables faster processing for large datasets. Whether it’s batch processing or real-time stream processing, Spark delivers low-latency data pipelines, making it ideal for businesses that need timely insights. Spark's performance advantages help businesses process terabytes or even petabytes of data with high efficiency.
2. Scalable Across Clusters
As a distributed system, Apache Spark can scale horizontally across multiple nodes in a cluster, making it highly adaptable to varying data sizes. At Datazone, this scalability ensures that no matter how large or complex your data pipelines grow, Spark handles the load without compromising speed.
3. Unified Data Processing
One of Spark’s key strengths is its versatility in managing different types of data workloads, whether it’s batch processing, machine learning, or real-time stream analytics. This unified processing capability makes Spark an ideal engine for the diverse workloads our customers manage within Datazone. It simplifies the tech stack by eliminating the need for multiple specialized systems.
Clickhouse: The Fast Columnar Database for Analytics
Clickhouse is an open-source columnar database specifically designed for online analytical processing (OLAP). It excels in high-performance analytics at scale, and here’s why it’s a perfect match for Datazone’s data ecosystem:
1. Blazing Fast Query Performance
Clickhouse is built for speed. Its columnar storage format allows it to read only the data necessary to answer a query, making it much faster than traditional row-based databases, especially when working with large datasets. In Datazone, this translates to sub-second query performance even on billions of rows of data, making it perfect for dashboards, reports, and ad-hoc analytics.
2. Efficient Data Storage
With its advanced compression algorithms, Clickhouse allows for much more efficient storage of large datasets. In a world where data is growing exponentially, keeping storage costs manageable is critical. Datazone’s customers benefit from reduced storage footprints while still accessing their data quickly and efficiently.
3. Handling Complex Analytical Workloads
Clickhouse excels in executing complex analytical queries, such as aggregations and multi-join queries, with a level of efficiency that few other databases can match. This makes it a natural fit for Datazone, where users expect fast insights from their data, no matter how complex the query.
How Datazone Simplifies Data Engineering with Spark and Clickhouse
While both Apache Spark and Clickhouse are powerful on their own, managing and orchestrating them in production environments can still be challenging. This is where Datazone comes in, simplifying the data engineering journey for our users.
1. Unified Platform for Data Processing and Analytics
At Datazone, we’ve brought together Spark and Clickhouse into a unified, easy-to-manage platform. Instead of configuring and deploying these engines separately, Datazone offers a seamless experience where you can run your distributed data pipelines with Apache Spark and query your data at lightning speed with Clickhouse—all from one place.
2. No Need to Manage Infrastructure
Setting up clusters, managing compute resources, and optimizing storage are tasks that can eat up valuable time for data engineers. Datazone abstracts the complexity of provisioning and managing infrastructure for both Apache Spark and Clickhouse. With Datazone, users can focus on building and running their data pipelines, while we handle the backend infrastructure.
3. Automated Scaling and Resource Management
One of the most common challenges in data engineering is scaling resources as data volumes grow. Datazone automates the provisioning of resources like Datazone Compute Units (DCUs), ensuring that your Spark and Clickhouse workloads have the compute and storage they need, without the overhead of manually tuning clusters or managing servers.
4. Optimized for Cost and Performance
We understand that balancing performance and cost is critical for our users. Datazone optimizes the use of both Spark and Clickhouse to ensure you get maximum performance at the most efficient cost. For example, we dynamically provision resources based on usage patterns, reducing unnecessary overhead while ensuring peak performance when you need it most.
5. End-to-End Pipeline Orchestration
Building and maintaining data pipelines often involves multiple tools and significant manual effort. Datazone streamlines the process by allowing you to build, manage, and monitor your entire pipeline— from ingesting data, processing it with Spark, to loading and querying it in Clickhouse—all in one place. This simplifies operations, reduces errors, and accelerates time-to-insight.
Conclusion
At Datazone, we believe that choosing the right foundational technologies is key to building a powerful, scalable, and efficient data platform. By combining Apache Spark for distributed data processing and Clickhouse for high-speed analytics, we ensure that our platform delivers top-tier performance and scalability.
However, the true value of Datazone lies in how we simplify the management of these technologies. From infrastructure management to pipeline orchestration, Datazone removes the complexity from data engineering, allowing you to focus on what matters most—extracting insights from your data.
Ready to experience the power of Apache Spark and Clickhouse without the headaches of managing them? Get started with Datazone today and see how we can simplify your data workflows.
Introduction
At Datazone, our mission is to simplify data engineering tasks while providing a powerful, scalable platform for managing and analyzing large-scale data. As we set out to build a comprehensive data and AI platform, we made the strategic decision to use Apache Spark and Clickhouse as our foundational engines. Why? Because they offer a perfect blend of scalability, performance, and flexibility, making them the best choices to support a wide range of data workloads.
In this blog, we'll explain why we've chosen Apache Spark and Clickhouse, and how Datazone simplifies managing data engineering tasks through these powerful engines.
Apache Spark: The Engine for Scalable and Distributed Data Processing
Apache Spark is a robust, open-source engine designed for distributed data processing, known for its ability to handle large-scale data efficiently across multiple clusters. Here's why it's at the heart of Datazone:
1. Speed and Performance
Spark's in-memory computing capability enables faster processing for large datasets. Whether it’s batch processing or real-time stream processing, Spark delivers low-latency data pipelines, making it ideal for businesses that need timely insights. Spark's performance advantages help businesses process terabytes or even petabytes of data with high efficiency.
2. Scalable Across Clusters
As a distributed system, Apache Spark can scale horizontally across multiple nodes in a cluster, making it highly adaptable to varying data sizes. At Datazone, this scalability ensures that no matter how large or complex your data pipelines grow, Spark handles the load without compromising speed.
3. Unified Data Processing
One of Spark’s key strengths is its versatility in managing different types of data workloads, whether it’s batch processing, machine learning, or real-time stream analytics. This unified processing capability makes Spark an ideal engine for the diverse workloads our customers manage within Datazone. It simplifies the tech stack by eliminating the need for multiple specialized systems.
Clickhouse: The Fast Columnar Database for Analytics
Clickhouse is an open-source columnar database specifically designed for online analytical processing (OLAP). It excels in high-performance analytics at scale, and here’s why it’s a perfect match for Datazone’s data ecosystem:
1. Blazing Fast Query Performance
Clickhouse is built for speed. Its columnar storage format allows it to read only the data necessary to answer a query, making it much faster than traditional row-based databases, especially when working with large datasets. In Datazone, this translates to sub-second query performance even on billions of rows of data, making it perfect for dashboards, reports, and ad-hoc analytics.
2. Efficient Data Storage
With its advanced compression algorithms, Clickhouse allows for much more efficient storage of large datasets. In a world where data is growing exponentially, keeping storage costs manageable is critical. Datazone’s customers benefit from reduced storage footprints while still accessing their data quickly and efficiently.
3. Handling Complex Analytical Workloads
Clickhouse excels in executing complex analytical queries, such as aggregations and multi-join queries, with a level of efficiency that few other databases can match. This makes it a natural fit for Datazone, where users expect fast insights from their data, no matter how complex the query.
How Datazone Simplifies Data Engineering with Spark and Clickhouse
While both Apache Spark and Clickhouse are powerful on their own, managing and orchestrating them in production environments can still be challenging. This is where Datazone comes in, simplifying the data engineering journey for our users.
1. Unified Platform for Data Processing and Analytics
At Datazone, we’ve brought together Spark and Clickhouse into a unified, easy-to-manage platform. Instead of configuring and deploying these engines separately, Datazone offers a seamless experience where you can run your distributed data pipelines with Apache Spark and query your data at lightning speed with Clickhouse—all from one place.
2. No Need to Manage Infrastructure
Setting up clusters, managing compute resources, and optimizing storage are tasks that can eat up valuable time for data engineers. Datazone abstracts the complexity of provisioning and managing infrastructure for both Apache Spark and Clickhouse. With Datazone, users can focus on building and running their data pipelines, while we handle the backend infrastructure.
3. Automated Scaling and Resource Management
One of the most common challenges in data engineering is scaling resources as data volumes grow. Datazone automates the provisioning of resources like Datazone Compute Units (DCUs), ensuring that your Spark and Clickhouse workloads have the compute and storage they need, without the overhead of manually tuning clusters or managing servers.
4. Optimized for Cost and Performance
We understand that balancing performance and cost is critical for our users. Datazone optimizes the use of both Spark and Clickhouse to ensure you get maximum performance at the most efficient cost. For example, we dynamically provision resources based on usage patterns, reducing unnecessary overhead while ensuring peak performance when you need it most.
5. End-to-End Pipeline Orchestration
Building and maintaining data pipelines often involves multiple tools and significant manual effort. Datazone streamlines the process by allowing you to build, manage, and monitor your entire pipeline— from ingesting data, processing it with Spark, to loading and querying it in Clickhouse—all in one place. This simplifies operations, reduces errors, and accelerates time-to-insight.
Conclusion
At Datazone, we believe that choosing the right foundational technologies is key to building a powerful, scalable, and efficient data platform. By combining Apache Spark for distributed data processing and Clickhouse for high-speed analytics, we ensure that our platform delivers top-tier performance and scalability.
However, the true value of Datazone lies in how we simplify the management of these technologies. From infrastructure management to pipeline orchestration, Datazone removes the complexity from data engineering, allowing you to focus on what matters most—extracting insights from your data.
Ready to experience the power of Apache Spark and Clickhouse without the headaches of managing them? Get started with Datazone today and see how we can simplify your data workflows.
Introduction
At Datazone, our mission is to simplify data engineering tasks while providing a powerful, scalable platform for managing and analyzing large-scale data. As we set out to build a comprehensive data and AI platform, we made the strategic decision to use Apache Spark and Clickhouse as our foundational engines. Why? Because they offer a perfect blend of scalability, performance, and flexibility, making them the best choices to support a wide range of data workloads.
In this blog, we'll explain why we've chosen Apache Spark and Clickhouse, and how Datazone simplifies managing data engineering tasks through these powerful engines.
Apache Spark: The Engine for Scalable and Distributed Data Processing
Apache Spark is a robust, open-source engine designed for distributed data processing, known for its ability to handle large-scale data efficiently across multiple clusters. Here's why it's at the heart of Datazone:
1. Speed and Performance
Spark's in-memory computing capability enables faster processing for large datasets. Whether it’s batch processing or real-time stream processing, Spark delivers low-latency data pipelines, making it ideal for businesses that need timely insights. Spark's performance advantages help businesses process terabytes or even petabytes of data with high efficiency.
2. Scalable Across Clusters
As a distributed system, Apache Spark can scale horizontally across multiple nodes in a cluster, making it highly adaptable to varying data sizes. At Datazone, this scalability ensures that no matter how large or complex your data pipelines grow, Spark handles the load without compromising speed.
3. Unified Data Processing
One of Spark’s key strengths is its versatility in managing different types of data workloads, whether it’s batch processing, machine learning, or real-time stream analytics. This unified processing capability makes Spark an ideal engine for the diverse workloads our customers manage within Datazone. It simplifies the tech stack by eliminating the need for multiple specialized systems.
Clickhouse: The Fast Columnar Database for Analytics
Clickhouse is an open-source columnar database specifically designed for online analytical processing (OLAP). It excels in high-performance analytics at scale, and here’s why it’s a perfect match for Datazone’s data ecosystem:
1. Blazing Fast Query Performance
Clickhouse is built for speed. Its columnar storage format allows it to read only the data necessary to answer a query, making it much faster than traditional row-based databases, especially when working with large datasets. In Datazone, this translates to sub-second query performance even on billions of rows of data, making it perfect for dashboards, reports, and ad-hoc analytics.
2. Efficient Data Storage
With its advanced compression algorithms, Clickhouse allows for much more efficient storage of large datasets. In a world where data is growing exponentially, keeping storage costs manageable is critical. Datazone’s customers benefit from reduced storage footprints while still accessing their data quickly and efficiently.
3. Handling Complex Analytical Workloads
Clickhouse excels in executing complex analytical queries, such as aggregations and multi-join queries, with a level of efficiency that few other databases can match. This makes it a natural fit for Datazone, where users expect fast insights from their data, no matter how complex the query.
How Datazone Simplifies Data Engineering with Spark and Clickhouse
While both Apache Spark and Clickhouse are powerful on their own, managing and orchestrating them in production environments can still be challenging. This is where Datazone comes in, simplifying the data engineering journey for our users.
1. Unified Platform for Data Processing and Analytics
At Datazone, we’ve brought together Spark and Clickhouse into a unified, easy-to-manage platform. Instead of configuring and deploying these engines separately, Datazone offers a seamless experience where you can run your distributed data pipelines with Apache Spark and query your data at lightning speed with Clickhouse—all from one place.
2. No Need to Manage Infrastructure
Setting up clusters, managing compute resources, and optimizing storage are tasks that can eat up valuable time for data engineers. Datazone abstracts the complexity of provisioning and managing infrastructure for both Apache Spark and Clickhouse. With Datazone, users can focus on building and running their data pipelines, while we handle the backend infrastructure.
3. Automated Scaling and Resource Management
One of the most common challenges in data engineering is scaling resources as data volumes grow. Datazone automates the provisioning of resources like Datazone Compute Units (DCUs), ensuring that your Spark and Clickhouse workloads have the compute and storage they need, without the overhead of manually tuning clusters or managing servers.
4. Optimized for Cost and Performance
We understand that balancing performance and cost is critical for our users. Datazone optimizes the use of both Spark and Clickhouse to ensure you get maximum performance at the most efficient cost. For example, we dynamically provision resources based on usage patterns, reducing unnecessary overhead while ensuring peak performance when you need it most.
5. End-to-End Pipeline Orchestration
Building and maintaining data pipelines often involves multiple tools and significant manual effort. Datazone streamlines the process by allowing you to build, manage, and monitor your entire pipeline— from ingesting data, processing it with Spark, to loading and querying it in Clickhouse—all in one place. This simplifies operations, reduces errors, and accelerates time-to-insight.
Conclusion
At Datazone, we believe that choosing the right foundational technologies is key to building a powerful, scalable, and efficient data platform. By combining Apache Spark for distributed data processing and Clickhouse for high-speed analytics, we ensure that our platform delivers top-tier performance and scalability.
However, the true value of Datazone lies in how we simplify the management of these technologies. From infrastructure management to pipeline orchestration, Datazone removes the complexity from data engineering, allowing you to focus on what matters most—extracting insights from your data.
Ready to experience the power of Apache Spark and Clickhouse without the headaches of managing them? Get started with Datazone today and see how we can simplify your data workflows.
Introduction
At Datazone, our mission is to simplify data engineering tasks while providing a powerful, scalable platform for managing and analyzing large-scale data. As we set out to build a comprehensive data and AI platform, we made the strategic decision to use Apache Spark and Clickhouse as our foundational engines. Why? Because they offer a perfect blend of scalability, performance, and flexibility, making them the best choices to support a wide range of data workloads.
In this blog, we'll explain why we've chosen Apache Spark and Clickhouse, and how Datazone simplifies managing data engineering tasks through these powerful engines.
Apache Spark: The Engine for Scalable and Distributed Data Processing
Apache Spark is a robust, open-source engine designed for distributed data processing, known for its ability to handle large-scale data efficiently across multiple clusters. Here's why it's at the heart of Datazone:
1. Speed and Performance
Spark's in-memory computing capability enables faster processing for large datasets. Whether it’s batch processing or real-time stream processing, Spark delivers low-latency data pipelines, making it ideal for businesses that need timely insights. Spark's performance advantages help businesses process terabytes or even petabytes of data with high efficiency.
2. Scalable Across Clusters
As a distributed system, Apache Spark can scale horizontally across multiple nodes in a cluster, making it highly adaptable to varying data sizes. At Datazone, this scalability ensures that no matter how large or complex your data pipelines grow, Spark handles the load without compromising speed.
3. Unified Data Processing
One of Spark’s key strengths is its versatility in managing different types of data workloads, whether it’s batch processing, machine learning, or real-time stream analytics. This unified processing capability makes Spark an ideal engine for the diverse workloads our customers manage within Datazone. It simplifies the tech stack by eliminating the need for multiple specialized systems.
Clickhouse: The Fast Columnar Database for Analytics
Clickhouse is an open-source columnar database specifically designed for online analytical processing (OLAP). It excels in high-performance analytics at scale, and here’s why it’s a perfect match for Datazone’s data ecosystem:
1. Blazing Fast Query Performance
Clickhouse is built for speed. Its columnar storage format allows it to read only the data necessary to answer a query, making it much faster than traditional row-based databases, especially when working with large datasets. In Datazone, this translates to sub-second query performance even on billions of rows of data, making it perfect for dashboards, reports, and ad-hoc analytics.
2. Efficient Data Storage
With its advanced compression algorithms, Clickhouse allows for much more efficient storage of large datasets. In a world where data is growing exponentially, keeping storage costs manageable is critical. Datazone’s customers benefit from reduced storage footprints while still accessing their data quickly and efficiently.
3. Handling Complex Analytical Workloads
Clickhouse excels in executing complex analytical queries, such as aggregations and multi-join queries, with a level of efficiency that few other databases can match. This makes it a natural fit for Datazone, where users expect fast insights from their data, no matter how complex the query.
How Datazone Simplifies Data Engineering with Spark and Clickhouse
While both Apache Spark and Clickhouse are powerful on their own, managing and orchestrating them in production environments can still be challenging. This is where Datazone comes in, simplifying the data engineering journey for our users.
1. Unified Platform for Data Processing and Analytics
At Datazone, we’ve brought together Spark and Clickhouse into a unified, easy-to-manage platform. Instead of configuring and deploying these engines separately, Datazone offers a seamless experience where you can run your distributed data pipelines with Apache Spark and query your data at lightning speed with Clickhouse—all from one place.
2. No Need to Manage Infrastructure
Setting up clusters, managing compute resources, and optimizing storage are tasks that can eat up valuable time for data engineers. Datazone abstracts the complexity of provisioning and managing infrastructure for both Apache Spark and Clickhouse. With Datazone, users can focus on building and running their data pipelines, while we handle the backend infrastructure.
3. Automated Scaling and Resource Management
One of the most common challenges in data engineering is scaling resources as data volumes grow. Datazone automates the provisioning of resources like Datazone Compute Units (DCUs), ensuring that your Spark and Clickhouse workloads have the compute and storage they need, without the overhead of manually tuning clusters or managing servers.
4. Optimized for Cost and Performance
We understand that balancing performance and cost is critical for our users. Datazone optimizes the use of both Spark and Clickhouse to ensure you get maximum performance at the most efficient cost. For example, we dynamically provision resources based on usage patterns, reducing unnecessary overhead while ensuring peak performance when you need it most.
5. End-to-End Pipeline Orchestration
Building and maintaining data pipelines often involves multiple tools and significant manual effort. Datazone streamlines the process by allowing you to build, manage, and monitor your entire pipeline— from ingesting data, processing it with Spark, to loading and querying it in Clickhouse—all in one place. This simplifies operations, reduces errors, and accelerates time-to-insight.
Conclusion
At Datazone, we believe that choosing the right foundational technologies is key to building a powerful, scalable, and efficient data platform. By combining Apache Spark for distributed data processing and Clickhouse for high-speed analytics, we ensure that our platform delivers top-tier performance and scalability.
However, the true value of Datazone lies in how we simplify the management of these technologies. From infrastructure management to pipeline orchestration, Datazone removes the complexity from data engineering, allowing you to focus on what matters most—extracting insights from your data.
Ready to experience the power of Apache Spark and Clickhouse without the headaches of managing them? Get started with Datazone today and see how we can simplify your data workflows.



